


AI-driven Algorithm Helps 7 Million Customers

Product used: custom sales chatbot.
Our client is a massive not-for-profit organisation in the USA. For over a hundred years, they have helped their customers find their way through thousands of viable options. To achieve this, our client has built algorithmic models that gather over 5.7 million data points from six different sources. Each year, these numbers are crunched to help over seven million customers find the right fit amongst over 6,000 options.
In 2016, our client saw the rise in chatbots and found it an opportunity to refresh their appeal. Instead of servicing their customers with complex, long-winded, and dull forms, why not transform the experience into a conversation? After a long year of trial and error using multiple DIY chatbot platforms, it became clear these wouldn’t cut it and, if they wanted things done properly, they needed the help from experts.
Enter ubisend.
Working backwards: from conversations to the data
When the client came to us and pitched their project, it seemed like a typical chatbot build. Their customers engage with the chatbot, follow a loose path of qualifying questions, and are presented with a list of suitable next steps. Your typical, run-of-the-mill solution.
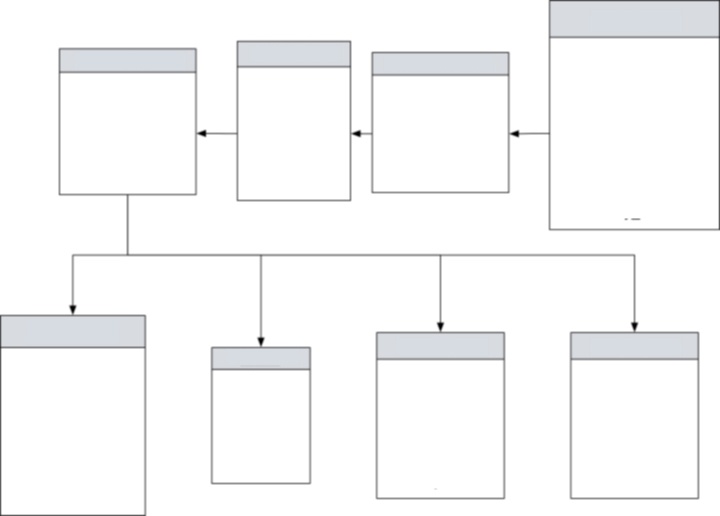
That was before we peeked under the hood. This fairly simple chatbot interaction was being powered by an extremely advanced and, moderately complex, algorithm. As ubisend took over this project, we realised there was a lot to be done to bring the algorithm to life and up to the standards required for the chatbot to perform.
We took a backwards approach. In a typical project, we would first lay the data groundwork, format and centralise it all before even contemplating the chatbot. For this project, we had to rewind the clocks and bring the client back a step.
Complex algorithm
The ubisend geeks first tackled data understanding and clean up.
Working with six different sources of data has a number of issues. Each source is uniquely defined, which makes sense when looking at them in a silo. However, to enable us to build a complex algorithm and artificial intelligence layer on top, we need to unify them under a common structure and labelling.
To do so, ubisend trawled through over 5.7m data points, created a centralised data dictionary for each, and populated them all into a relational database. This database allows us to understand the correlations between each data point.
Once the data was cleaned and unified enough to the standards we have and so we could work with it, we were able to start tackling the algorithm. The algorithm needed to take any combination of inputs a potential customer could enter, and then output the correct suggestion.
For raw processing, our algorithm could run any combination from 170,226,000 to upwards of 5.7 million data points and, almost instantly, return an optimal suggestion.
Back to the conversation
Thanks to our step backwards, we now have the perfect solid foundation to start building conversations onto. The data team handed the project back to the conversation and design team. Collecting data from users can be a gruelling process. Thankfully, our geeks knowshow to bring a machine to life and give it just enough personality to make it a pleasurable experience.
Today, our client’s chatbot is used by both their customers (over 7 million of them and counting) and their internal staff. As we have rebuilt their algorithm from the ground up, ubisend is able to work closely with their internal research team to optimise and develop the next phase(s) of the project.
Start leveraging the power of big data and conversational software today. Talk to chatbot experts.








